On Monday one of my friends came down with some symptoms of coronavirus, and unfortunately that seems to have coincided with the week where the UK's testing system started to come apart at the seams. I found myself working from home and looking for a way to learn a new language. I'm going to write a bit of a blog about my experience of getting to grips with using Python in a bit more in depth way than I have maybe before. I'm going to be using the website http://www.pythonchallenge.com/ to try and learn some new aspects of Python. Coming into this, I've used the langauge sporadically and I'm excited to see what can be done.
Challenge 1
Starting the first challenge I'm greeted by an image of a sign in a field with some off centre numbers, with a hint reading: Try to change the url address.
The URL currently reads http://www.pythonchallenge.com/pc/def/0.html, I have no idea what the goal is right now, and feel like I could be in over my head, but I suppose lets try and do what the hint suggests and research how we might be able to change the address.
An inital research found that we might be able to use urllib. As I've got nothing else to go on, lets give it a go. After having a go playing arount with the urllib basic commands, I thought I would try changing the url by hand just to see what might happen.
I changed the 0 to a 1 in the original url to read: http://www.pythonchallenge.com/pc/def/1.html
This brought up a new webpage reading : 2**38 is much much larger. I was unsure if this notation means 2^38, but I gave it a go. I initially just jammed 2^38 into google, but then realised I should probably try and work out how to do it in Python, as that is the point of the challenge. It was then that I realised I didn't actually know how to raise numbers to a power in Python.
Ahhh silly me, 2**32 is how to raise 2 to the power of 32 in Python.
>>> 2**38
274877906944
Entering http://www.pythonchallenge.com/pc/def/274877906944.html brings us to a new web page with challenge number 2!! Looks like I was over complicating it by going into trying to attack their url and change it, I will try simpler approaches moving forwards.
Challenge 2
Challenge 2 shows a webpage with a piece of paper with 3 letters. It initially looks like a cipher.
K -> M
o -> Q
E -> G
g fmnc wms bgblr rpylqjyrc gr zw fylb. rfyrq ufyr amknsrcpq ypc dmp. bmgle gr
gl zw fylb gq glcddgagclr ylb rfyr'q ufw rfgq rcvr gq qm jmle. sqgle
qrpgle.kyicrpylq() gq pcamkkclbcb. lmu ynnjw ml rfc spj.
The hint reads: everybody thinks twice before solving this.
Not sure what to make of the hint this time. I sort of want to try the letter translations we are given on the hint text and see if that leaves us with an extra clue or something.
Lets have a go at doing that in Python then, and see what we get. We need to store the 2 codes in strings, and itterate over the letters of the strings replacing any that we know from the clues. How do we itterate over letters in a string? Turns out its very simple, we can just declare a string using quotation marks, and then itterte over the string using:
for a in encoded:
Then its simple enough to use some if statements to find and replace known letters. As I'm supposed to be learning, lets see if there are any handy functions for doing something like this. This feels rather caveman, there must be something out there already that will do a better job.
str.replace(old, new[,max]) seems like a useful candidate.
Well just applying the single transformations to the code and the hint didn't really result in anything. Perhaps it is a full cipher shift? Lets see how large the alphabetical shifts are for the 3 clues they've given us. Again, lets try and do it in Python. I would be able to do it by assigning 26 variables integer values based on their position in the alphabet, but again lets try and avoid the caveman approach. (Starting to wonder if I should start living in a cave at this point... ).
There is a string.index() function which we can use to work out the index of the letters we are translating. In Python3, the function has been updated to string.ascii_lowercase.index('b'), this will return a 1 with 'a' returning 0.
With these tools it seems like we might be able to decode the message in 2/3 lines. Small hitch along the way is that the ascii_lowercase.index() is not safe if you pass it a non-standard character, like an integer. A better solution might be to create a mapping between the 2 alphabets we need, and then do a test to see if we are working with valid characters before we apply the mapping. Heres the solution I came up with.
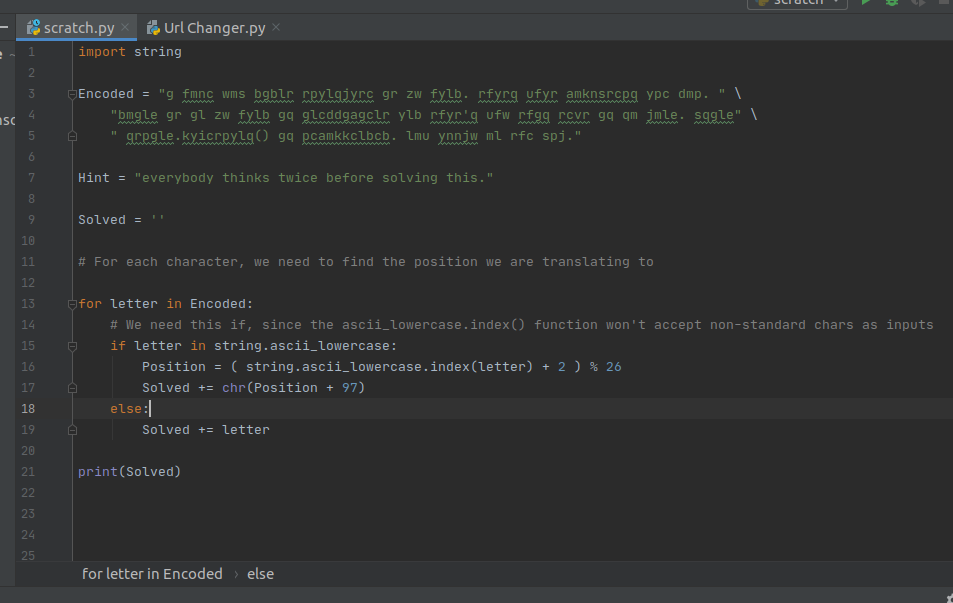
After solving the ceaser shift, the code translates to:
i hope you didnt translate it by hand. thats what computers are for. doing it in by hand is inefficient and that's why this text is so long. using string.maketrans() is recommended. now apply on the url.
Back to feeling like a caveman. Lets give their recommended method a go.
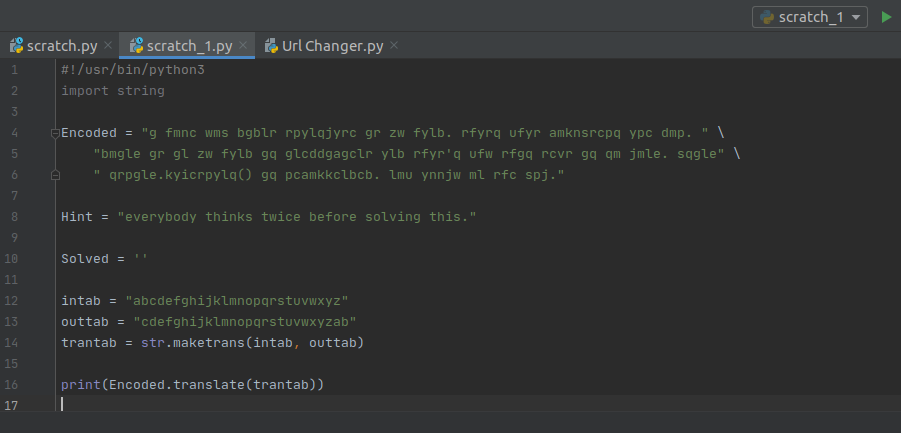
Applying the same translation to the url gives us jvvr://yyy.ravjqpejcnngpig.eqo/re/fgh/ocr.jvon. Which doesn't seem to give us much, but lets give it a go and try it. The top link on google is a link to the PythonChallenge website, which takes us to a blank webpage, telling us we're permitted to see the solution to problem 1. This gives us a full solution page of all the ways people have solved the problem.
My favourite was the one liner we can run from the command line: curl http://www.pythonchallenge.com/pc/def/map.html | tr a-z c-za-b
Onto the next challenge.... Well at least I'd like to go onto the next challenge, but there doesn't seem to be a straightforward way to get there. A quick google indicated we only apply the translation to the last 3 letters of the url to get to http://www.pythonchallenge.com/pc/def/ocr.html.
Challenge 3
Challenge 3 shows a blurry picture of an open book, you can't make out any of the letters, and the hint reads: recognize the characters. maybe they are in the book, but MAYBE they are in the page source.
It seems that we need to get the page source to get acces to the challenge. Using curl http://www.pythonchallenge.com/pc/def/ocr.html I had a quick look at the page source, and sure enough hidden within the page source is the challenge... :
find rare characters in the mess below: %%$@_$^__#)^)&!_+]!*@&^}@[@%]()%+$&[(_@%+%$*^@$^!+]!&_#)_*}{}}!}_]$[%}@[{_@#_^{*
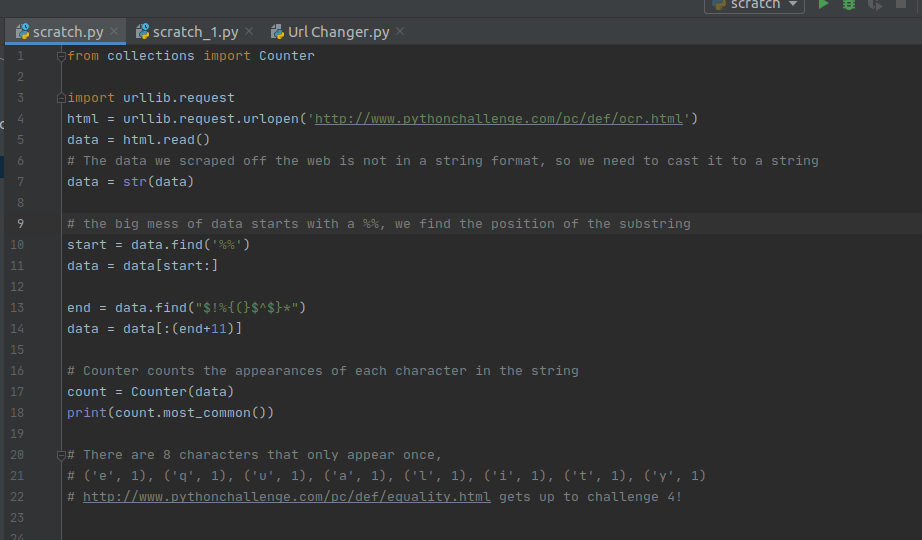
I feel its a bit of a cop out using curl, so lets try and work out how to get the page source in python. This seems like a good first attempt at getting all the HMTL content of the webpage.
The next step is to chop down the html to something we can actually work with, and then try and find the rare characters. Here is the solution I ended up with. Counter was a very useful function for a challenge like this.
Challenge 4
Challenge 4 seems to be relatively similar to the last one in that the challenge is hidden in the page source. Picture is of 7 candles, with a caption: One small letter, surrounded by EXACTLY three big bodyguards on each of its sides. Since the challenge is called equality it seems we need to find a substring in the page source that matches this pattern. I was expecting there only to be one solution which matches the pattern, but it turned out there was a large number of substrings which matched up with this requirement.
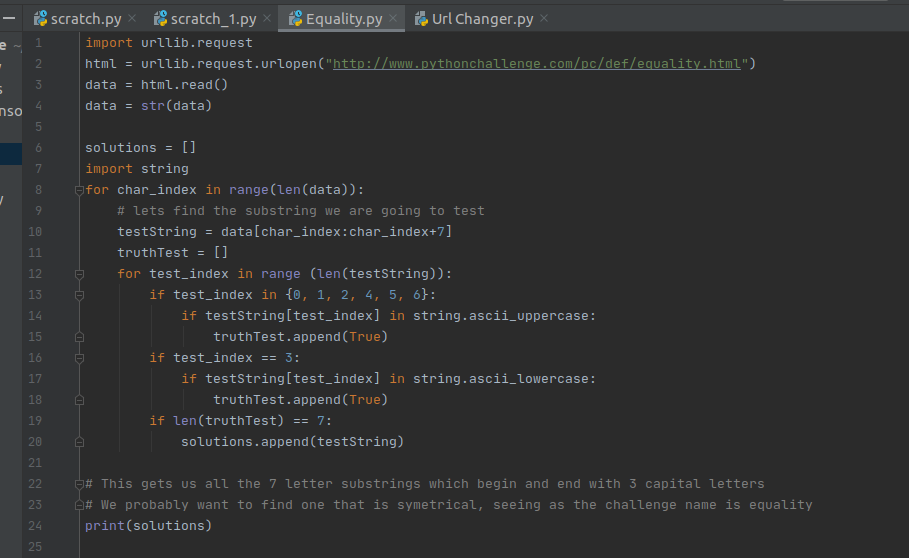
This was my original attempt to go down this route but it turned out to be a bit of a dead end. I didn't really notice but it seems that the pattern requirement is a bit stricter than I originally thought. It seems we also care about whether the character before and after the string are capitals or not, after a bit of googling around the problem it seems that the regular expression package is a good fit for the problem. We can use it to search for the pattern of letters we are looking for in one line.
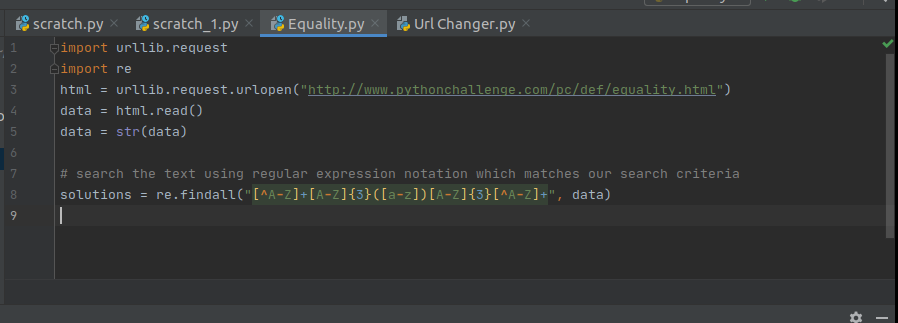
We also only care about the single lowercase letters, and putting them all together spells out linked list. The solution to this challenege.
Challenge 5
Challenge 5 is a linked list of webpages. It starts off at the page http://www.pythonchallenge.com/pc/def/linkedlist.php?nothing=12345, which is a simple page of html with a single clue: "the next nothing is 44827", replacing 12345 with the number leads to another similar webpage which has another next nothing number. It seems the idea is to chain our way through the webpages, grabbing the next nothing value from the page source, and then getting the next webpage's data.
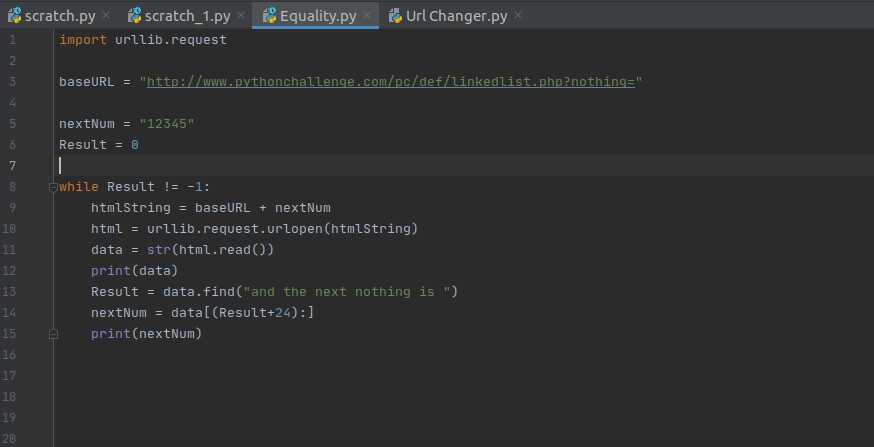
This problem was a really satisfying one to solve, I think the creators of the website did a really good job with it. Here was my solution that more or less worked the whole way. There were 2 trip ups that I managed to miss, one is that they do ask you to manually change the value once in the chain of values, and then they throw in a line designed to throw you off if you were only searching the page source for a number, rather than the specific 'nothing'. The final page in the chain tells us the next challenge can be found at peak.html.
One final thing to leave here is the .encoding() function. I was finding the way I've been getting the page source for webpages to be quite clumsy, in that it dumps the whole page source into a single string, and it doesn't really deal well with all the newline characters. This little addition allows us to get the page source in a much nicer format.

Challenge 6
I had no idea on this one and had to google a solution. The challenge page shows a picture of a hill with a hint caption: pronounce it. The page source includes a html peakhell object, which is supposed to lead us to the Python module pickle! Going with the first page I found, peakhell sounds like pickle, which is a Python object serialization module... not such a fan of this one. But at least a helpful solution was easy to find.
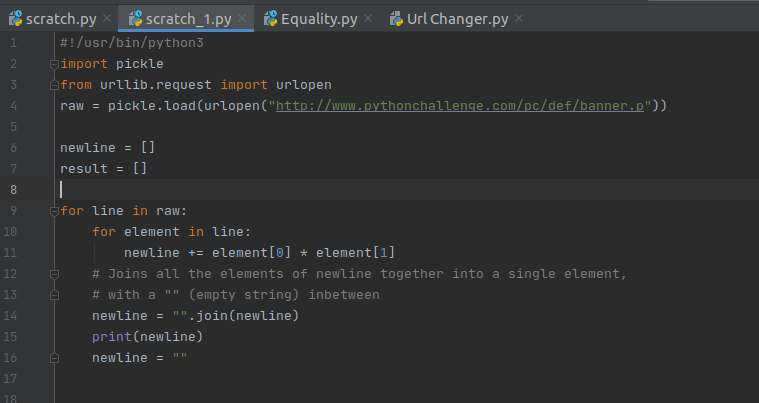
The page source hints that there is a banner included in the page. Navigating to the html page of the banner: http://www.pythonchallenge.com/pc/def/banner.p, we can see a bunch of data. We can decode the data using pickle, and it then becomes clear that the data is a list of tuples. The tuples consist of pairs of characters and integers. Multiplying and joining the characters together shows us a message. I really wouldn't have got very far in this one without significant help. I feel I need to understand what exactly the pickle module is doing for us here beyond a curosory understanding that is decoding this stream of data.
Challenge 7
The page source of this challenge is quite obscure, no real guidance as to what we're supposed to be doing. The picture of a zip in the challenge main page, and the commented out zip in the page source point towards us potentially needing to do something with the Python zip() function.
A common thing in this challenge seems to be that clues should be applied to the web address. Navigating to http://www.pythonchallenge.com/pc/def/zip.html shows us a blank page with a caption: yes, find the zip. Could be referring to a zip file, or again back to something we can use with zip(). Looking at the page source, there doesn't seem to be anything there. Changing the webpage to http://www.pythonchallenge.com/pc/def/channel.zip, gave us a zip download.
The zip download contains a bunch of .txt files and a readme. The readme reads:
welcome to my zipped list.
hint1: start from 90052
hint2: answer is inside the zip
It seems we need to itterate between the list of files, similar to how we itterated through the webpages before. How do we open files again in Python? This code segment chains through the files using the next nothing to find its way through to the end. At the end of the chain there is a little message saying: collect the comments. How on earth do I collect the comments?
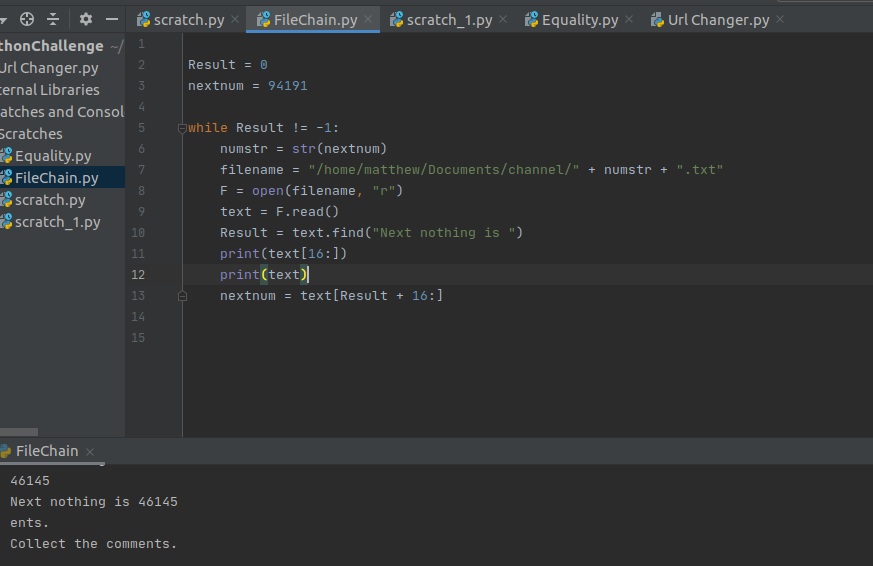
It seems that the way to collect the comments is to use the zipfile library, and save the zip file archive.